
Google Releases Gemma 4 12B For Everyday Notebooks
The rise of AI has pushed memory prices higher and higher.
Google understands this problem and has now introduced Gemma 4 12B, a new model designed to fill the gap left by earlier versions.
The goal is simple: let general users run high-quality AI without needing huge amounts of RAM or expensive server-level hardware.
This makes Gemma 4 12B an interesting choice for people who want local AI performance on ordinary notebooks.
A Mid-Sized Model For Practical AI Use
Back in April, Google released several versions of Gemma 4.
Some models were smaller and aimed at mobile devices. Others were larger and designed for heavier workloads.
However, there was still no clear middle option that balanced performance and hardware requirements.
That is where Gemma 4 12B comes in.
This model is designed for users who want to run AI on a standard notebook with only around 16GB of RAM or VRAM.
That makes it much lighter than the bigger 26B model.
For users who do not own a workstation or server-class machine, this is a big step forward.
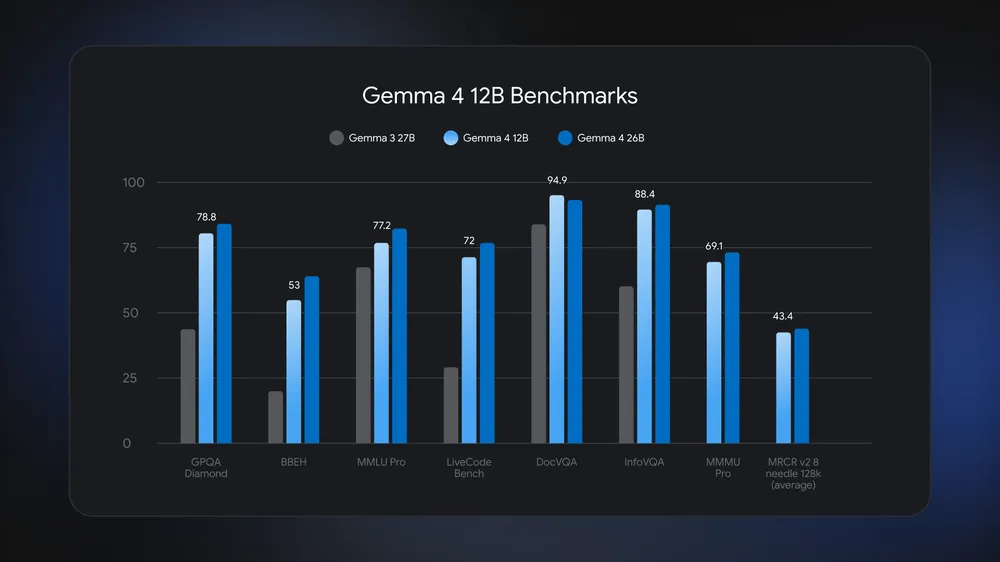
Multi-Token Prediction Makes It Faster
One of the most impressive features of Gemma 4 12B is Multi-Token Prediction, or MTP.
This technology helps the system use available processing cycles to predict future tokens.
As a result, the model can work faster and more efficiently.
This is also the first time the Gemma family includes this feature from the start without requiring extra setup.
That makes the model more convenient for general users.
With MTP, this mid-sized model becomes smart enough to handle complex tasks and AI Agent workflows more smoothly.
Better Multimodal Processing
Google also improved how Gemma 4 12B handles different types of data.
Normally, many models need separate encoders for images or audio.
The 12B model changes this approach by using a new embedding module that removes unnecessary steps.
This lets image data enter the model more directly.
For audio, the system converts raw signals into vectors in a way that works similarly to text.
This reduces memory burden and lowers latency.
The result is a more efficient model that can better support different kinds of input without demanding too much from the machine.
Easier Access Through Common Tools
Users who want to try Gemma 4 12B can access it through tools such as LM Studio or Google AI Edge Gallery.
This makes testing the model easier without forcing users into a complicated setup process.
For those who want stronger privacy and full local control, the model can also be downloaded directly.
The file size is around 18GB.
Users can get it through platforms such as Kaggle and Hugging Face.
This gives people more flexibility depending on how they want to use the model.
Local AI Without Constant Cloud Dependence
Gemma 4 12B is an important move for Google.
The model shows how powerful AI can become more accessible on ordinary portable devices.
Instead of depending on cloud systems all the time, users can run capable AI locally on their own machines.
This opens the door for developers, creators, and general users to build and experiment more easily.
It also gives users more control over privacy, workflow, and performance.
For anyone with a 16GB notebook, this model could become a practical way to experience stronger local AI.
A Strong Step For Accessible AI
Google Gemma 4 12B reflects a larger shift in AI development.
Powerful models are no longer limited only to massive cloud platforms or expensive hardware.
A model that can run on a regular notebook makes AI experimentation more approachable.
It could help students, creators, developers, and everyday users explore AI tools without needing extreme hardware upgrades.
If future models become even smarter and more energy-efficient, local AI could become a normal part of everyday computing.
For now, Gemma 4 12B looks like a strong option for users who want smoother AI performance without buying a server-grade machine.
Google Gemma 4 12B feels like the kind of AI release that matters because it targets normal users, not just massive data centers. Running a capable model on a 16GB notebook makes local AI feel more realistic. If this direction continues, powerful offline AI may become less of a luxury and more of a standard tool.
Origin: Arstechnica





